



If you want to build AI products that are unique, valuable, and fast, don't do what everybody else is doing. I'll show you what to do instead.
The vast majority of AI products being built right now are just wrappers over other models, such as those that essentially involve calling ChatGPT over an API.
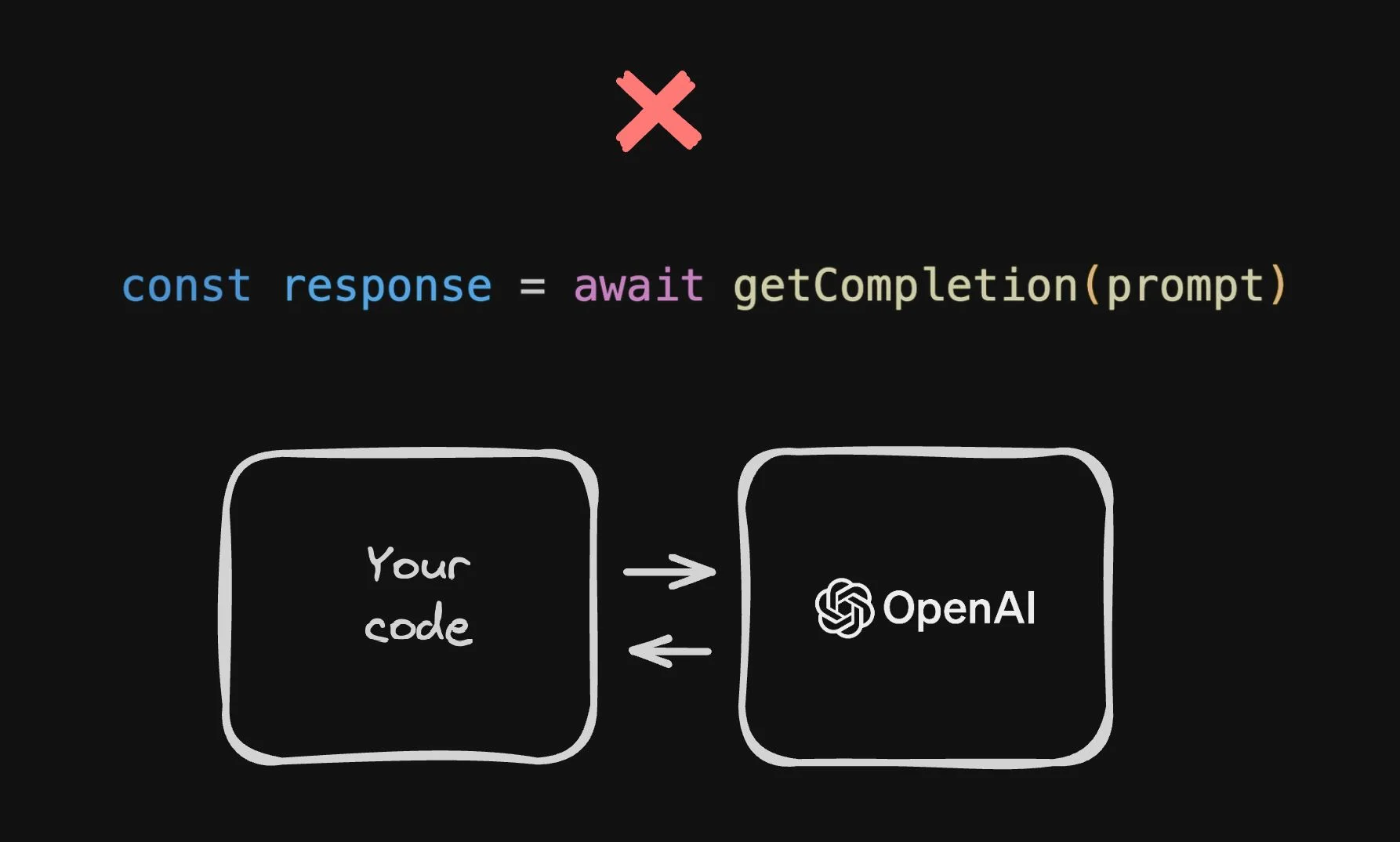
While that's incredibly easy — you send natural language in and get natural language out — and it can do some really cool things, there are some major problems with this approach that people are running into.
But, there's a solution for them that I'll show you.
The first major issue is this is not differentiated technology.
If you've noticed that one person creates a chat with a PDF app, and then another dozen people do too, and then OpenAI builds that into ChatGPT directly, it's because nobody there actually built something differentiated.
They use a simple technique, with a pre-trained model, which anyone can copy in a very short period of time.
When building a product whose unique value proposition is some type of advanced AI technology, it's a very risky position to be so easy to copy.
Now, of course, there's a whole spectrum here.

If you're on the right side of the spectrum, where all you made was a button that sends something to ChatGPT and gets a response back that you showed your end users — where ChatGPT basically did all the work —you're at the highest risk here.
On the other end, if you actually built some substantial technology and LLMs where OpenAI has only assisted with a small but crucial piece, then you may be in a better position, but you're still going to run into two other major issues.
The first major issue you'll run into is cost. The best part of a large language model is their broad versatility, but they achieve this by being exceptionally large and complex, which makes them incredibly costly to run.
As an example, per the Wall Street Journal, recently GitHub Copilot was losing money per user, charging $10, but on average cost $20, and some users cost GitHub up to $80 per month.
And the worst part is you probably don't need such a large model. Your use case probably doesn't need a model trained on the entirety of the Internet because 99.9% of that training covers topics that have nothing to do with your use case.
So, while the ease of this approach might be tempting, you could run into this common issue where what your users want to pay is less than what it costs to run your service on top of large language models.
Even if you're the rare case where the cost economics might work out okay for you, you're still going to hit one more major issue: LLMs are painfully slow.
Now, this isn't a huge problem for all applications. For use cases such as ChatGPT, where reading one word at a time is the norm, this might be okay.
However, in applications where text isn't meant to be read word-for-word, and the entire response is expected before proceeding to the next step in the workflow, this can pose a significant issue.
As an example, when we started working on Builder's Visual Copilot, where we wanted one button click to turn any design into high-quality code, one of the approaches we explored was using an LLM for the conversion.
One of the key issues we encountered was the significant time delay. When passing an entire design specification into an LLM and receiving a new representation token by token, generating a response would take several minutes, making it impractical.
And because the representation returned by the LLM is not what a human would perceive, the loading state was just a spinner — not ideal.
If for some reason, performance still isn't an issue for you, and your users don't care about having a slow and expensive product that's easy for your competitors to copy, you're still likely to run into another major issue — LLMs can't be customized that much.
Yes, they all support fine-tuning, and fine-tuning can incrementally help the model get closer to what you need. But in our case, we tried using fine-tuning to provide Figma designs and get code out the other side.
But no matter how many examples we gave the model, it didn't improve. We were left with something slow, expensive, and inferior quality. And that's when we realized we had to take a different approach.
What did we have to do instead? We had to create our own toolchain.
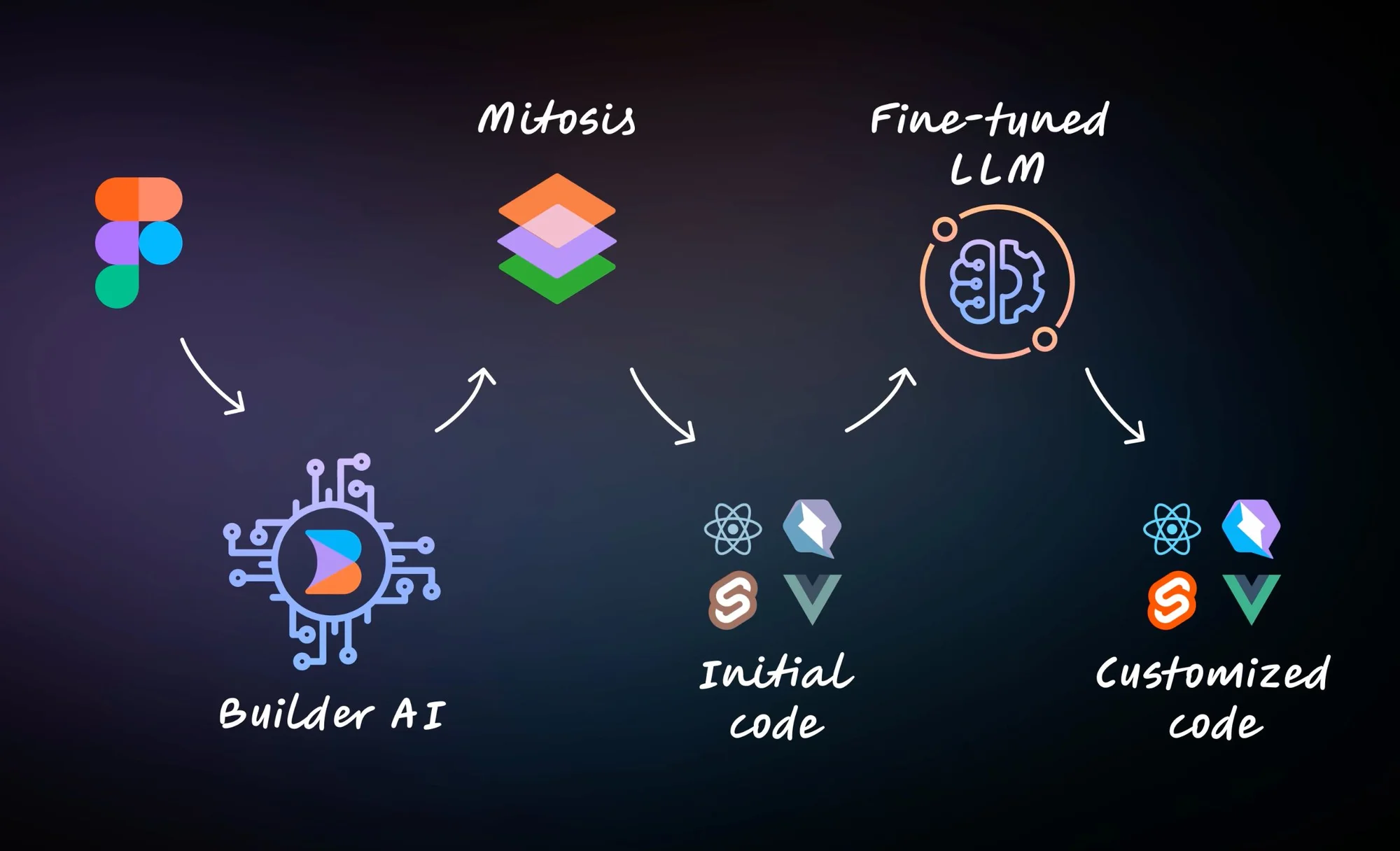
In this case, we combined a fine-tuned LLM, a custom compiler that we wrote, and a custom-trained model.
And it wasn't as hard as it might seem.These days, you don't have to be a data scientist or a Ph.D. in machine learning to train your own model.
Any moderately experienced developer can do it. This way, you can build something that is way faster, way more reliable, far cheaper, and far more differentiated. You won't have to worry about copycat products or open-source clones spawning overnight, either.
And this isn't just a theory. Most, if not all, advanced AI products are built like this.
A lot of people have a major misconception about how AI products are built. I've noticed that they often think that all the core tech is handled by one super smart model, trained with tons of inputs to give exactly the right output.

Take self-driving cars, for example. A lot of people have the impression that there's a giant model that takes in all these different inputs like cameras, sensors, GPS, and so on, and that it crunches it through the AI, and then out comes the action on the other side, such as a right turn.

But this could not be farther from the truth.That car driving itself is not one big AI brain.
Instead of a whole toolchain of specialized models, all connected with normal code — such as models for computer vision to find and identify objects, predictive decision-making, anticipating the actions of others, or natural language processing for understanding voice commands — all of these specialized models are combined with tons of just normal code and logic that creates the end result — a car that can drive itself.

Now, keep in mind, autonomous vehicles is a highly complex example that includes many more models than I've mentioned here.
For building your own product, you won't need something nearly this complex, especially when starting out.
Remember, self-driving cars didn't spawn overnight. My 2018 Prius is capable of parking itself, stopping automatically when too close to an object, and many other things using little to no AI.
Over time, more and more layers were added to cars to do more and more advanced things, like correcting lane departure, or eventually making entire decisions to drive from one place to another.
But like all software, these things are built in layers, one on top of the next.
I highly recommend you explore the approach we used for Visual Copilot for your own AI solutions. It's a straightforward but counterintuitive approach.
The most important thing is to not use AI at first.
Explore the problem space using normal programming practices to determine what areas need a specialized model in the first place.
Remember, making “supermodels” is generally not the right approach. We don't want to send tons of Figma data into a model and get finished code out the other side.
That would be an outrageously complex problem to solve with just one model. And when you factor in all the different frameworks we support, and styling options and customizations, it would be unfeasible to retrain this model with all this additional data.
It likely would have become so complex, slow, and expensive that our product might never have even shipped.
Instead, we considered the problem and said, well, how can we solve this without AI? How far can we get before it gets impossible without the types of specialized decision-making AI is best at?
So we broke the problem down and said, okay, we need to convert each of these nodes to things we can represent in code.
We needed to understand, in detail, working with elements such as images, backgrounds, and foregrounds. And most importantly, we needed to intricately understand how to make any input responsive.
After that, we started considering more complex examples and realized there are lots of cases where many, many layers would need to be turned into one image.
We started writing hand-coded logic to say if a set of items is in a vertical stack that should probably be a flex column, and items that are side by side should probably be a flex row.
We got as far as we could creating all these different types of sophisticated algorithms to automatically transform designs to responsive code before we started hitting limits.
In my experience, wherever you think the limit is, it's probably a lot further. But, at a certain point, you'll find some things are just near impossible to do with standard code.
For example, automatically detecting which layers should turn into one image, is something that human perception is really good at understanding, but this isn't necessarily normal imperative code. In our case, we wrote all this in JavaScript.
Lucky for us, training your own object detection model to solve this need with AI is not that hard. For example, products like Google's Vertex AI has a range of common types of models that you can efficiently train yourself — one of which is object detection.
I can choose that with a GUI and then prepare data and just upload it as a file.
For a well-established type of model like this, all it comes down to is creating the data.
Now, where things get interesting is finding creative ways of generating the data you need.
One awesome, massive free resource for generating data is simply the Internet.
One way we explored approaching this was using puppeteer to automate opening websites in a web browser, taking a screenshot of the site, and traversing the HTML to find the img tags.
We then used the location of the images as the output data and the screenshot of the webpage as the input data. And now we have exactly what we need — a source image and coordinates of where all the sub-images are to train this AI model.
Using these techniques where we fill in the unknowns with specialized AI models and combine them is how we're able to produce end results like this: I can just select my design, click Generate code, wait only about one second, and launch into Builder.io.
Then in Builder, we get a completely responsive website with high-quality code that you can customize completely. It supports a wide variety of frameworks and options, and it's all super fast because all of our models are specially built just for this purpose.
We offer this at an exceptionally low cost, providing a generous free tier, and it's tremendously valuable for our customers, helping them save lots of time.
The best part is that this is only the beginning.
One of the best parts of this approach is that we completely own the models so we can constantly improve them. We aren't just wrapping somebody else's model.
If you're fully dependent only on someone else's model, like OpenAI, there's no guarantee it's going to get smarter, faster, or cheaper for your use case in any guaranteed timeline. And your ability to control that with prompt engineering and fine-tuning is severely limited.
But since we own our own model, we're making significant improvements every day.
When new designs come in that don't import well — which still happens as it's in beta — we rely on user feedback to improve at a rapid cadence, shipping improvements every single day.
With this approach, we never have to worry about a lack of control. For instance, when we started talking to some large and privacy-focused companies as potential early beta customers, one of the most common pieces of feedback was that they were not able to use OpenAI or any products using OpenAI.
Their privacy requirements prioritize making sure their data never goes into systems that they don't allow.
In our case, because we control the entire technology, we can hold our models to an extremely high privacy bar. Thank goodness, because we would’ve lost out on some serious business had we been dependent on other companies (like many others are).
And for the LLM step, we can either turn it off (because it's purely nice to have) or companies can plug in their own LLM. Those LLMs might be an entirely in-house built model, a fork of llama2, their own enterprise instance of OpenAI, or something else entirely.
So, if you want to build AI products, I highly recommend taking a similar approach as Builder.
As strange as it sounds, avoid using AI for as long as possible in your project. Then, when you start finding particular problems that standard coding doesn't solve well — but well-established AI models can — start generating your own data and training your own models with a wide variety of tools you can find off-the-shelf.
Connect your model(s) to your code only where they're needed.
And I want to emphasize this: use AI for as little as possible. At the end of the day, “normal” code is the fastest, most reliable, most deterministic, most easy to debug, easy to fix, easy to manage, and easy to test code you will ever have.
But the magic will come from the small but critical areas you use AI models for.
Can’t wait to see the awesome things you build.
Builder.io visually edits code, uses your design system, and sends pull requests.
Builder.io visually edits code, uses your design system, and sends pull requests.
 Connect a Repo
Connect a Repo











